When to Use Arrays and Vectors in Rust
In Rust we have two built-in ways to store multiple elements in order: arrays and vectors. Each type has its place, but most often we will want to use vectors. Arrays meanwhile can be used for performance optimizations and to reduce memory usage.
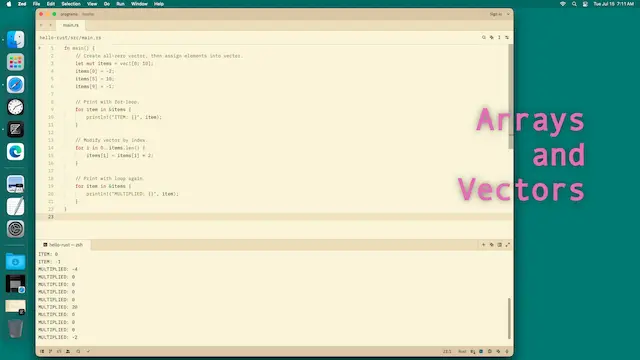
An array can store only a fixed number of elements—it cannot be resized. So it might have 10 i32 elements. Meanwhile a vector has a resizable buffer, so it can grow from 0 elements to millions of elements (with each push call).
Vectors tend to be easier to use, but arrays have some advantages:
HashMap.In places where performance is not critical, vectors are an easier and more convenient choice. They also lead to more resilient code in case more elements than expected are needed. But arrays have an important role in optimization, and can reduce memory usage.
Is Multithreading Worth It
The program fails in an unexpected way, but only once every ten or twenty times it is run. This is a hard-to-debug problem: what causes the failure, and how can it be reproduced? In many programming languages, programs that use threads may have this sort of bug.
Most programming languages do not force developers to access all fields in a thread-safe way. So the burden falls on the developer to ensure the code is correct, and a hard-to-reproduce bug will not occur.
One language that enforces thread-safe access to fields is Rust:
Mutex, which means we cannot read or write it without having exclusive access to it (locking it).Mutex for mutable writes eliminates many multithreading bugs in Rust programs.In languages like C# or Go it is possible to unsafely modify data while other threads are reading the fields. This can lead to complicated bugs where the program works correctly, but only 99% of the time. Without "fearless concurrency" as in Rust, I feel multithreading should be largely avoided—it is more trouble than it's worth in most cases.
Are Properties Useful in C#
In object-oriented programming, an object needs to respond to requests for data. For example, a Color object might need to return an RGB value when needed, and a name string when that is required.
In C# we are supposed to use properties for this purpose. But do properties really have any meaningful advantage over a "Getter" method, and are they worthwhile? The generated code for a property is the same as for a GetRgb or GetName method.
We should use properties in C# because it is convention, and other types might expect properties for data-binding purposes. But methods could have been used instead of properties for these reasons:
GetName that have the same meaning as a Name property.There is no reason we must have properties in addition to methods. And at the end of the day, it is unclear whether the excess syntax and complexity is worth the benefits. And in my view, calling a method like GetName is probably clearer than using a Name property.
Understanding Temporal Locality
When writing a program, it is tempting to try to count instructions to analyze its performance. Clearly a program that runs 100 instructions should be faster than one that runs 110. But many factors can muddy the analysis.
Consider the processor's memory cache—if we load a file from the disk into memory, we can access that file again with minimal delay as it is in the CPU cache. This means that operations that act on a region of memory are faster if they are done nearer in time to one another.
This concept is known as temporal locality, and it has some implications:
At times I have had a program that opens many files, and then tries to process them all at once. But by understanding temporal locality, it is possible to optimize for the CPU cache—we open a file, process it fully, and then move to the next file. This can lead to a measurable performance improvement.
Is Object-Oriented Programming Worth It
Some decades ago a new programming concept became popular: object-oriented programming. The basic unit of program design would become the class, and classes could contain methods and fields, and inherit from other classes. Runtime types could determine what methods were called.
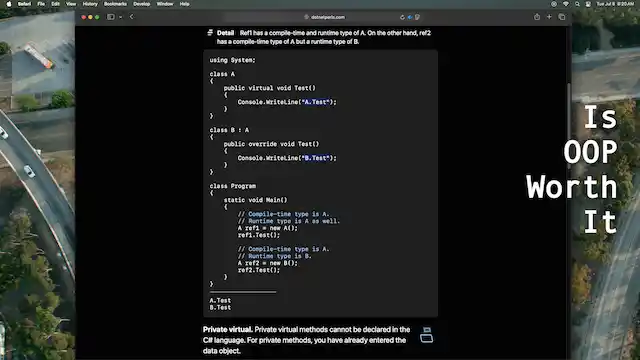
All was great, and programs became perfect, with no further bugs ever being introduced. Back in reality, though, OOP introduced a lot of complexity, and it was hard for even experienced developers to grasp. And after learning about OOP and writing about it, I think of it mainly as a program organization strategy.
Here are some of my realizations about OOP:
if-statements and switches on a field—it seems "more advanced" to call a derived or virtual method, but in reality, it is just another conditional branch.if-statements, but they are just more complex to use, and the end result is the same.In conclusion, object-oriented programming is nothing special when it comes to the runtime execution of programs. But it makes it possible to organize programs in a more complex (and possibly harder-to-understand) way. These organizational constructs can be beneficial on larger programs, but are rarely worthwhile on smaller ones.
The Problem With Swift
Swift is a general-purpose programming language with clear syntax. When I first began learning Swift around the year 2010, I was excited about the language and felt it could be one of the leading programming languages in the future.
However, as years passed, I began to feel disillusioned about Swift. The major problem I encountered was that each time the language was updated, many of my example programs stopped working. The language kept breaking itself on each version. This was not just a pre-1.0 language issue—Swift 1.0 had been released already.
Even in the Swift 5.0 era, things as simple as looping over the characters in a string kept changing. Programs would not compile in newer compilers. Function arguments now had to be specified in a different way, and tons of errors and warnings would appear on previously-correct code.
A computer language is not an art project—it is something that people rely on to build programs. Perhaps early Swift versions were not yet ready to be released, and Apple wanted to continue changing the language to fit their internal needs for macOS and iOS programs. In any case Swift (at least in 2010) ended up being a poor choice for outside developers.
When to Use a Struct in C#
When I was first learning how to program C#, I wanted to use structs in strategic places. It seemed to make sense—structs could somehow make my programs better and speed them up somehow.
Over time, I started to realize most of the places I used structs would have been better off (or just as well-off) with classes. Structs are a way to have a type that is stored inline, without a reference to the heap memory. In .NET things like int, DateTime, or KeyValuePair are structs—these are all types that require minimal memory.
Unless you have a need to create a new numeric type, it is best to avoid structs. Here are some drawbacks of structs:
List, more memory needs to be copied—this causes slowdowns.struct is larger than a reference, a List of structs may be larger in memory (and slower) than a List of class references.The C# language is designed mostly around classes. Structs are more of a feature that is needed for the standard library—to create types like int, DateTime, or KeyValuePair. If you have types similar to those, a struct can help performance slightly, but even then a class may be superior. In general, classes are preferred.
When to Use a Lookup Table
Code often has "hot" spots that are reached repeatedly—and these places may have a branching condition. For example, in a spelling checker, each byte of the input might need to be checked to see if it is part of a word, whitespace, or punctuation.
Lookup tables can be used to reduce the amount of branching done in these places. Usually a lookup table has 256 bytes, one array element for each possible byte, and can store values like a boolean or another byte. In performance, lookup tables occupy space on the processor's level 1 cache. Sometimes, a delay can occur trying to copy the memory to the cache.
For this reason, lookup tables can actually slow down programs—the delay in copying memory is greater than the time saved in reducing branching. Lookup tables still have an advantage in some places:
Benchmarks tend to make lookup tables appear faster than they are, as the table remains in the processor's cache throughout the benchmark run. Still, if enough branches are saved, the lookup table will improve overall performance. My personal rule is that any time a table is accessed more than 20 times in a function, and the results of the table are hard to predict, it is worth using a lookup table.
When to Use StringBuilder in C#
It is common to need to append one string to another in C# programs. This is called concatenation. In languages where strings can be modified after being created, this is efficient—but in C#, strings are immutable and concatenation leads to a new string creation.
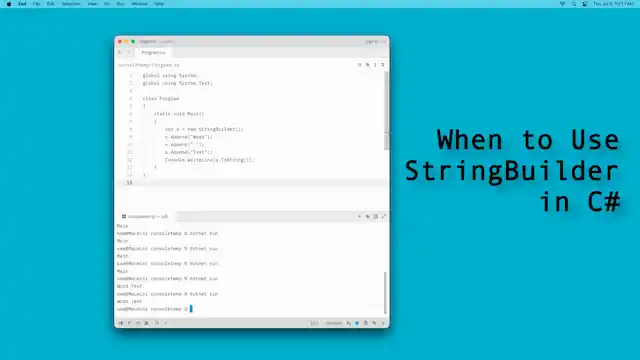
Creating too many new strings will cause excessive allocations and copying of memory. This can lead to big performance problems. StringBuilder can eliminate this problem by providing a buffer into which all the strings are copied, with fewer allocations.
We can use StringBuilder when:
string from many existing strings.In the case of two strings, it can be faster just to concatenate the strings directly, but it is also acceptable to use StringBuilder. If further appends are needed, the StringBuilder will prevent future performance problems. So it is useful as a preventative measure against excess string copies.
Advantages of Enums in Rust
I do not know everything about every computer language, or even every one I write about on this site. Instead, I learn as I go along. From other languages like C# I was familiar with the concept of enums—types that store known values and can be referenced by name.

But in Rust, enums have an additional feature—they are an algebraic data type. This means a value in an enum can reference some data—like a struct instance, a String, a tuple or a number.
In practice, this means we can use a single enum to refer to multiple data types:
enum with two variants, each with a different data type, can be tested in a match statement and we can evaluate the data at runtime.enum instance will have until runtime.So we can create a Color, and it could have a value of Red with a String, or a value of Blue with a usize instead. And we can refer the Color as meaning either Red or Blue—and a String or usize only in appropriate cases. This can simplify some programs where we must return many types of data from a single function.