Choosing Between HashMap and HashSet
Most programming languages have types like HashMap (also known as Dictionary, Hashtable or map) and HashSet (also known as set). The map types can store both a key and a value, and the set types just store a key. No duplicate keys are allowed—these collections check for uniqueness.
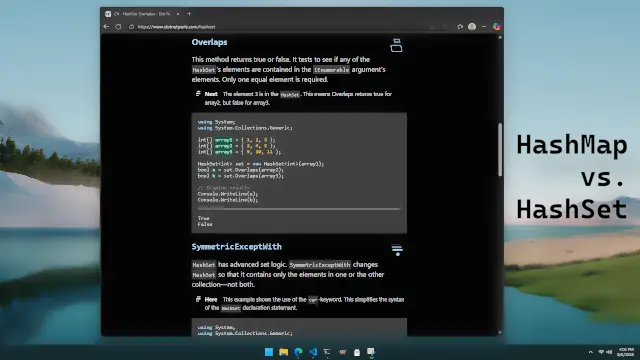
It seems like it is common sense to do certain things with a map, and other things with a set. But is this really necessary? It is possible to do everything with just the map types, and never use the set types. We can just use any value—like a bool with the value true, or the integer 1.
In any case, we typically use sets when:
Intersect or Overlaps are required.In my experience, normal programs rarely require mathematical set operations. And it makes about as much sense just to use true to indicate a value instead of using an entirely different type like HashSet. There is no likely performance impact. If we are using a Dictionary elsewhere, it may reduce code size to reuse that class for set operations, however.
Initialization Time in Programs
Suppose we have a program that must process a file. We can use different algorithms to process the file—one version processes data faster, but has a greater initialization time than the other. Which should we choose?
For a program that processes one small file, it is faster overall to avoid a high initialization cost. But if we have many files to process, or even a single large file, it is better to spend the time initializing the faster data structure.
The undecidability of software is one of my favorite things about it. One version is faster on large amounts of data, and the other on small amounts. In compiler theory, this is referred to as "undecidability"—it is impossible to tell which is better unless we consider all the possible use cases of the program.
But in my opinion, given the interest in "big data" in modern times, it is probably better just to pay the initialization cost—you might want to process a lot of data later (even if you don't know it yet).
Benefits of Arena Allocation
This is something that has confused me for a long time—what exactly does the term "arena allocation" refer to, and what good is it? Does a developer need to write a fancy "arena" allocator, or can a simpler approach also fill the requirement?
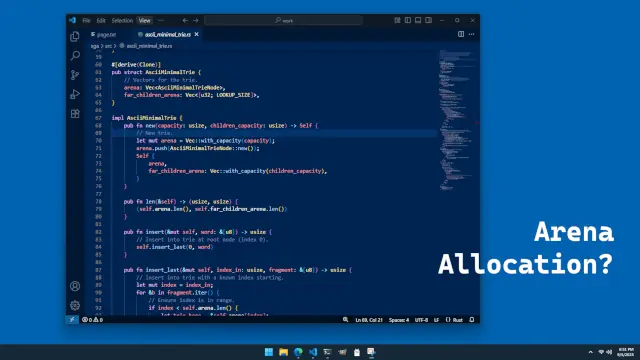
The term is confusing, but the concept makes perfect sense. Suppose you create a list (or array or vector) of objects in a single allocation. Each object can be referenced by an index. This list can serve as the arena allocator's backing store—we can keep track of what objects are used and referenced based on their indexes.
For example, in a trie data structure:
The "arena" for this design eliminates a lot of overhead, and reduces the number of allocations down to a minimum. One allocation can handle thousands of objects (depending on the language you are using). And pointers to these objects can be compressed down to 4 or even 2 bytes. Arena allocation is just managing any number of objects within a vector or list—and it's great for performance.
Using Single Bits for Bools
Suppose you have a class (or struct, depending on your language of choice) that has a bool field. This bool indicates something important or is some kind of flag. Each class instance can be accessed as an element of an array, so it has an index.
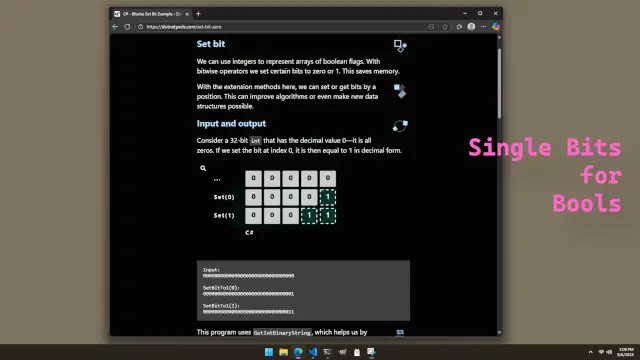
It seems at first that each class instance must use one byte for the bool field. But there is another way—not necessarily better, but more memory-efficient: we can use another array to store each flag as a single bit.
Each byte has 8 bits, so if we want to access the appropriate byte in the array for a class in our program, we can just its index and divide it by 8. Then a modulo division will give us the exact bit position in that byte.
Is this approach of using separate arrays to minimize memory usage (also called data-oriented programming, or arena allocation) always better? No, it is not—it reduces memory locality in some cases, and causes extra instructions to be executed to address the byte array. But if you have many objects you are dealing with, consider using single bits to represent bools.
When to Use Implicit Types (Like Var)
Most programming languages these days have implicit types—this is where we can use var, let, or some other keyword in place of a type like string or int. This feature can come in handy when dealing with more verbose type names—like Dictionary or HashMap types particularly. But exactly when should a developer use these implicit types?
My opinion is:
int, it is probably better to still use var or let as changing the type to an Int64 (or whatever) will not require you to change the var, but it will require you to change an int.Basically, var and let cut down on how much code people (or AIs as the case may be today) have to read. And when you refactor a type to have a different name, references to it that are using var or let don't need to be changed, reducing your work load.
I think, in languages like C#, var is nearly always better. In Rust and Swift we have let and everything is implicitly-typed by default. In Go we can use var, or just the special operator that assigns a new variable. In C++ (not covered on this site) we have auto which has the same effect.
Lookup Tables for Code Readability
It has been shown that lookup tables are often not a great optimization. In fact, they can slow down programs when used in place of direct value tests in if and switch. But after a recent experience I have started liking lookup tables more.
Over the last couple weeks I took it upon myself to implement a code highlighter—you know, the logic that makes code light up like a Christmas tree. This requires endless testing of bytes that must come before, after, or within keywords and other highlighted blocks.
With the initial implementation, I had a lot of direct byte tests. The code was pretty ugly—and had some bugs. I decided to rewrite the code with lookup tables—byte arrays of 256 elements that can replace direct value tests. And the end result? The code was much easier to read, and I felt better about its overall quality.
It is likely the lookup tables did not speed up the logic, but they improved the code. I think the lesson here is that performance is not everything—a more balanced perspective, where readability, correctness, and of course performance are considered is key.
List Dedup Across Languages
Programmers are usually the kind of people who like to have everything organized—after all, a large part of programming is organizing data structures in programs. Consider a list that has many elements—and some of them may be repeated or duplicates. Programming languages often offer built-in methods to eliminate the duplicates.
In the C# language, we have a method called Distinct that is part of System.Linq. When called, it eliminates duplicates in an IEnumerable and returns the result—we may need to call ToList to get back to a List.
In Rust, we have a dedup function on the Vector type. This requires that the vector be sorted (or in groups of equal elements), or it will not work correctly—it works by looping through the elements and checking to see if there are any duplicates next to each other. If you are going to rewrite it in Rust, remember dedup.
In Go, we have a function in the slices package called slices.Compact. This works the same as the Rust dedup function—it removes repeated elements in a sorted slice. The slice must be sorted (or have same elements next to each other somehow).
Understanding iter and into_iter in Rust
Sometimes it is worthwhile to think deeply on, or reflect upon, functions you use often in a language. Consider iter and into_iter in Rust. These create iterators and then we can loop over elements in a for-loop.
As I wrote in my article about this subject, iter returns references, and into_iter returns the original values. But the key difference between iter and into_iter is not the return values—it is that into_iter consumes the variable—it is "moved" to the iterator's ownership. Iter meanwhile just acts upon a reference of the original variable.
This means that:
Into_iter can return the original values in the collection, as it has ownership of them.Into_iter will cause a variable to be unavailable for later use in a function.Iter can be called in multiple places in a function without any moved value errors.The important thing is that into_iter takes ownership of the collection, and iter does not. In Rust, the for-loop on a collection implicitly calls into_iter—for beginners, changing this to iter can eliminate moved value errors.
Understanding Zip Iterators
Sometimes it is useful to think deeply about a function that can be found in many programming languages. There must be some reason the function is found in so many places, right? Consider the zip function—it receives two iterators, and returns an element from each, on each call.
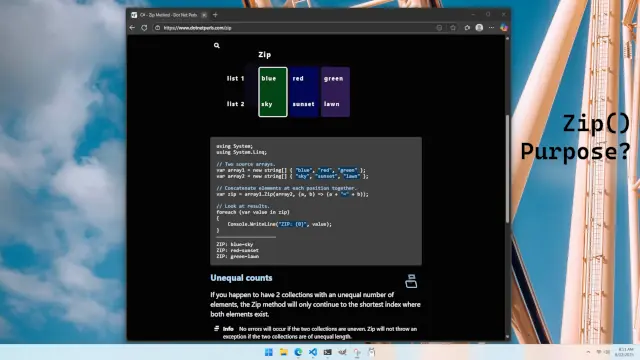
I have never used zip much, and I wondered what it might be good for. Am I missing something? In languages like C# it is part of System.Linq as Zip, and in Python and Rust it is zip.
Think of a program that has two arrays, and modifies one of the arrays—so we end up with a before-array, and an after-array. Then, we could call zip and iterate over both arrays at once. In each iteration, we could see if the before-element equals the after-element. This would eliminate the need to use indexes to iterate over both arrays at once.
So zip has a couple benefits—it lets us enforce some logic that two arrays are similar enough that they can be "zipped" together. And then we can avoid using indexes to access elements in each array. It does seem like a small improvement over not using zip—and I can see why so many languages might include a zip function. For code samples, this site has articles about zip for C# and Python.
Code Benefits From Separation of Concerns
Recently I wanted to improve how a certain feature worked in a program. It involved fuzzy string search, and the implementation was rather fuzzy itself—it was spread out everywhere. To fix this, I added a trie data structure. With a new component, I could isolate the logic—the program became easier to reason about.
By separating the parts of a program—also known as separation of concerns—we can make development easier. We can organize a large problem as a group of smaller problems. And a single component (like a file or class) can solve one of those smaller problems.
Every language allows for this approach. Some languages refer to objects or classes, and others to structs or files. The developer gets a feeling of accomplishment for having added a new component to the project, and the overall program becomes better.
Even new trends like vibe coding (coding using LLMs) can be used. We can have ChatGPT generate a new class or file, and then use it from the rest of the program. Once tested and reviewed, the code is good to go—and this should rightly make the developer feel a sense of accomplishment.